MemRoPE: Training-Free Infinite Video Generation via Evolving Memory Tokens
*Equal Contribution
Abstract
Autoregressive diffusion enables real-time frame streaming, yet existing sliding-window caches discard past context, causing fidelity degradation, identity drift, and motion stagnation over long horizons. Current approaches preserve a fixed set of early tokens as attention sinks, but this static anchor cannot reflect the evolving content of a growing video.
We introduce MemRoPE, a training-free framework with two co-designed components. Memory Tokens continuously compress all past keys into dual long-term and short-term streams via exponential moving averages, maintaining both global identity and recent dynamics within a fixed-size cache. Online RoPE Indexing caches unrotated keys and applies positional embeddings dynamically at attention time, ensuring the aggregation is free of conflicting positional phases.
These two mechanisms are mutually enabling: positional decoupling makes temporal aggregation well-defined, while aggregation makes fixed-size caching viable for unbounded generation. Extensive experiments validate that MemRoPE outperforms existing methods in temporal coherence, visual fidelity, and subject consistency across minute- to hour-scale generation.
Methodology
MemRoPE tackles the long-form video generation problem by solving the inherent limitations of fixed-size KV caches in autoregressive models. Extending past context indefinitely is memory-prohibitive, while aggressively truncating context leads to identity loss.
Our solution relies on two key innovations:
- Memory Tokens: Instead of dropping old tokens or selecting and retaining discrete anchor tokens, we maintain a fixed number of 'memory tokens' that continuously absorb information from new frames using an Exponential Moving Average (EMA). This provides a compressed, evolving summary of the entire video history.
- Online RoPE Indexing: Standard Rotary Positional Embeddings (RoPE) entangle positional information with the keys, making EMA aggregation destructive due to phase cancellation. We decouple positional embeddings from the cached keys, applying RoPE only online during the attention calculation, enabling clean temporal aggregation.
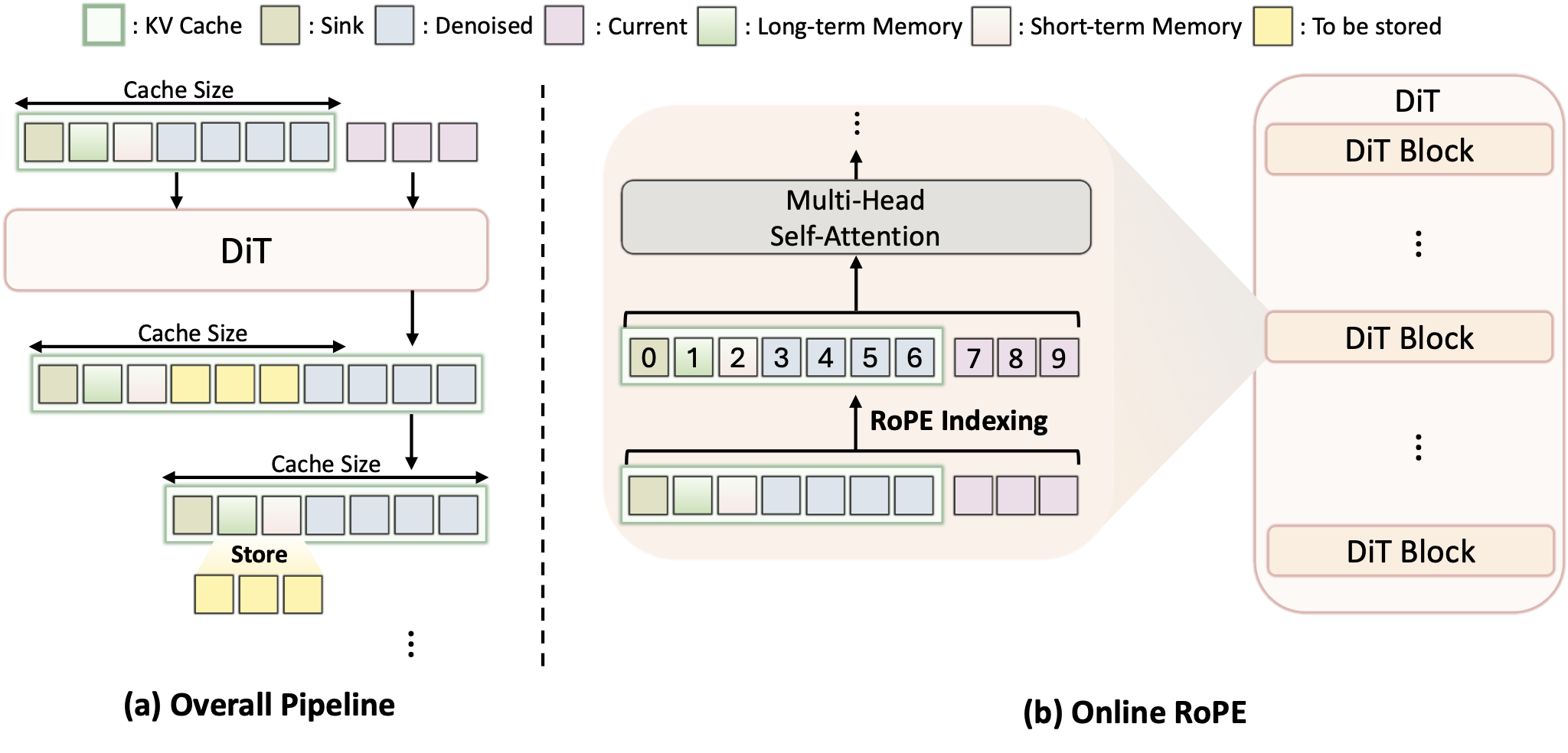
Figure 2. Overview of the MemRoPE framework.
Showcases
Explore various high-fidelity video generation showcases across different scenes and prompt conditions.
Comparisons
MemRoPE exhibits strong prompt compliance, smooth transitions, and high long-range consistency while enabling infinite video generation.
We evaluate MemRoPE alongside Deep Forcing and ∞-RoPE on two autoregressive base models: SelfForcing and LongLive, a long-video finetuned model. Baseline methods show weaker long-range consistency and progressive quality degradation on longer videos.
Ablation Study
We ablate the two streams of MemRoPE to validate their individual contributions.
Conclusion
We have presented MemRoPE, a training-free inference framework that enables unbounded video generation without suffering from memory constraints or identity degradation. By systematically decoupling the positional embeddings from the KV cache state and aggregating the historical keys through exponential moving averages, we elegantly compress global identity and local dynamics into a finite set of memory tokens.
Our comprehensive evaluations verify that MemRoPE maintains robust subject consistency, structural coherence, and visual quality over significantly extended time horizons—such as a continuous one hour of generated video—outperforming existing truncation and static anchoring baselines. MemRoPE pushes the frontier of infinite generation capabilities for autoregressive diffusion models without incurring any additional training costs.
Citation
@article{kim2026memrope,
title={MemRoPE: Training-Free Infinite Video Generation via Evolving Memory Tokens},
author={Kim, Youngrae and Hu, Qixin and Kuo, C.-C. Jay and Beerel, Peter A.},
journal={arXiv preprint},
year={2026}
}